Matthew Palmer: The Mediocre Programmer's Guide to Rust

Me: Hi everyone, my name s Matt, and I m a mediocre programmer. Everyone: Hi, Matt. Facilitator: Are you an alcoholic, Matt? Me: No, not since I stopped reading Twitter. Facilitator: Then I think you re in the wrong room.Yep, that s my little secret I m a mediocre programmer. The definition of the word hacker I most closely align with is someone who makes furniture with an axe . I write simple, straightforward code because trying to understand complexity makes my head hurt. Which is why I ve always avoided the more academic languages, like OCaml, Haskell, Clojure, and so on. I know they re good languages people far smarter than me are building amazing things with them but the time I hear the word endofunctor , I ve lost all focus (and most of my will to live). My preferred languages are the ones that come with less intellectual overhead, like C, PHP, Python, and Ruby. So it s interesting that I ve embraced Rust with significant vigour. It s by far the most complicated language that I feel at least vaguely comfortable with using in anger . Part of that is that I ve managed to assemble a set of principles that allow me to almost completely avoid arguing with Rust s dreaded borrow checker, lifetimes, and all the rest of the dark, scary corners of the language. It s also, I think, that Rust helps me to write better software, and I can feel it helping me (almost) all of the time. In the spirit of helping my fellow mediocre programmers to embrace Rust, I present the principles I ve assembled so far.
Neither a Borrower Nor a Lender Be
If you know anything about Rust, you probably know about the dreaded borrow checker .
It s the thing that makes sure you don t have two pieces of code trying to modify the same data at the same time, or using a value when it s no longer valid.
While Rust s borrowing semantics allow excellent performance without compromising safety, for us mediocre programmers it gets very complicated, very quickly.
So, the moment the compiler wants to start talking about explicit lifetimes , I shut it up by just using owned values instead.
It s not that I never borrow anything; I have some situations that I know are borrow-safe for the mediocre programmer (I ll cover those later).
But any time I m not sure how things will pan out, I ll go straight for an owned value.
For example, if I need to store some text in a struct or enum, it s going straight into a String.
I m not going to start thinking about lifetimes and &'a str; I ll leave that for smarter people.
Similarly, if I need a list of things, it s a Vec<T> every time no &'b [T] in my structs, thank you very much.
Attack of the Clones
Following on from the above, I ve come to not be afraid of .clone().
I scatter them around my code like seeds in a field.
Life s too short to spend time trying to figure out who s borrowing what from whom, if I can just give everyone their own thing.
There are warnings in the Rust book (and everywhere else) about how a clone can be expensive .
While it s true that, yes, making clones of data structures consumes CPU cycles and memory, it very rarely matters.
CPU cycles are (usually) plentiful and RAM (usually) relatively cheap.
Mediocre programmer mental effort is expensive, and not to be spent on premature optimisation.
Also, if you re coming from most any other modern language, Rust is already giving you so much more performance that you re probably ending up ahead of the game, even if you .clone() everything in sight.
If, by some miracle, something I write gets so popular that the expense of all those spurious clones becomes a problem, it might make sense to pay someone much smarter than I to figure out how to make the program a zero-copy masterpiece of efficient code.
Until then clone early and clone often, I say!
Derive Macros are Powerful Magicks
If you start .clone()ing everywhere, pretty quickly you ll be hit with this error:
error[E0599]: no method named clone found for struct Foo in the current scope
This is because not everything can be cloned, and so if you want your thing to be cloned, you need to implement the method yourself.
Well sort of.
One of the things that I find absolutely outstanding about Rust is the derive macro .
These allow you to put a little marker on a struct or enum, and the compiler will write a bunch of code for you!
Clone is one of the available so-called derivable traits , so you add #[derive(Clone)] to your structs, and poof! you can .clone() to your heart s content.
But there are other things that are commonly useful, and so I ve got a set of traits that basically all of my data structures derive:
#[derive(Clone, Debug, Default)]
struct Foo
// ...
Every time I write a struct or enum definition, that line #[derive(Clone, Debug, Default)] goes at the top.
The Debug trait allows you to print a debug representation of the data structure, either with the dbg!() macro, or via the :? format in the format!() macro (and anywhere else that takes a format string).
Being able to say what exactly is that? comes in handy so often, not having a Debug implementation is like programming with one arm tied behind your Aeron.
Meanwhile, the Default trait lets you create an empty instance of your data structure, with all of the fields set to their own default values.
This only works if all the fields themselves implement Default, but a lot of standard types do, so it s rare that you ll define a structure that can t have an auto-derived Default.
Enums are easily handled too, you just mark one variant as the default:
#[derive(Clone, Debug, Default)]
enum Bar
Something(String),
SomethingElse(i32),
#[default] // <== mischief managed
Nothing,
Borrowing is OK, Sometimes
While I previously said that I like and usually use owned values, there are a few situations where I know I can borrow without angering the borrow checker gods, and so I m comfortable doing it.
The first is when I need to pass a value into a function that only needs to take a little look at the value to decide what to do.
For example, if I want to know whether any values in a Vec<u32> are even, I could pass in a Vec, like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(numbers)
println!("EVENS!");
fn has_evens(numbers: Vec<u32>) -> bool
numbers.iter().any( n n % 2 == 0)
Howver, this gets ugly if I m going to use numbers later, like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(numbers)
println!("EVENS!");
// Compiler complains about "value borrowed here after move"
println!("Sum: ", numbers.iter().sum::<u32>());
fn has_evens(numbers: Vec<u32>) -> bool
numbers.iter().any( n n % 2 == 0)
Helpfully, the compiler will suggest I use my old standby, .clone(), to fix this problem.
But I know that the borrow checker won t have a problem with lending that Vec<u32> into has_evens() as a borrowed slice, &[u32], like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(&numbers)
println!("EVENS!");
fn has_evens(numbers: &[u32]) -> bool
numbers.iter().any( n n % 2 == 0)
The general rule I ve got is that if I can take advantage of lifetime elision (a fancy term meaning the compiler can figure it out ), I m probably OK.
In less fancy terms, as long as the compiler doesn t tell me to put 'a anywhere, I m in the green.
On the other hand, the moment the compiler starts using the words explicit lifetime , I nope the heck out of there and start cloning everything in sight.
Another example of using lifetime elision is when I m returning the value of a field from a struct or enum.
In that case, I can usually get away with returning a borrowed value, knowing that the caller will probably just be taking a peek at that value, and throwing it away before the struct itself goes out of scope.
For example:
struct Foo
id: u32,
desc: String,
impl Foo
fn description(&self) -> &str
&self.desc
Returning a reference from a function is practically always a mortal sin for mediocre programmers, but returning one from a struct method is often OK.
In the rare case that the caller does want the reference I return to live for longer, they can always turn it into an owned value themselves, by calling .to_owned().
Avoid the String Tangle
Rust has a couple of different types for representing strings String and &str being the ones you see most often.
There are good reasons for this, however it complicates method signatures when you just want to take some sort of bunch of text , and don t care so much about the messy details.
For example, let s say we have a function that wants to see if the length of the string is even.
Using the logic that since we re just taking a peek at the value passed in, our function might take a string reference, &str, like this:
fn is_even_length(s: &str) -> bool
s.len() % 2 == 0
That seems to work fine, until someone wants to check a formatted string:
fn main()
// The compiler complains about "expected &str , found String "
if is_even_length(format!("my string is ", std::env::args().next().unwrap()))
println!("Even length string");
Since format! returns an owned string, String, rather than a string reference, &str, we ve got a problem.
Of course, it s straightforward to turn the String from format!() into a &str (just prefix it with an &).
But as mediocre programmers, we can t be expected to remember which sort of string all our functions take and add & wherever it s needed, and having to fix everything when the compiler complains is tedious.
The converse can also happen: a method that wants an owned String, and we ve got a &str (say, because we re passing in a string literal, like "Hello, world!").
In this case, we need to use one of the plethora of available turn this into a String mechanisms (.to_string(), .to_owned(), String::from(), and probably a few others I ve forgotten), on the value before we pass it in, which gets ugly real fast.
For these reasons, I never take a String or an &str as an argument.
Instead, I use the Power of Traits to let callers pass in anything that is, or can be turned into, a string.
Let us have some examples.
First off, if I would normally use &str as the type, I instead use impl AsRef<str>:
fn is_even_length(s: impl AsRef<str>) -> bool
s.as_ref().len() % 2 == 0
Note that I had to throw in an extra as_ref() call in there, but now I can call this with either a String or a &str and get an answer.
Now, if I want to be given a String (presumably because I plan on taking ownership of the value, say because I m creating a new instance of a struct with it), I use impl Into<String> as my type:
struct Foo
id: u32,
desc: String,
impl Foo
fn new(id: u32, desc: impl Into<String>) -> Self
Self id, desc: desc.into()
We have to call .into() on our desc argument, which makes the struct building a bit uglier, but I d argue that s a small price to pay for being able to call both Foo::new(1, "this is a thing") and Foo::new(2, format!("This is a thing named name ")) without caring what sort of string is involved.
Always Have an Error Enum
Rust s error handing mechanism (Results everywhere), along with the quality-of-life sugar surrounding it (like the short-circuit operator, ?), is a delightfully ergonomic approach to error handling.
To make life easy for mediocre programmers, I recommend starting every project with an Error enum, that derives thiserror::Error, and using that in every method and function that returns a Result.
How you structure your Error type from there is less cut-and-dried, but typically I ll create a separate enum variant for each type of error I want to have a different description.
With thiserror, it s easy to then attach those descriptions:
#[derive(Clone, Debug, thiserror::Error)]
enum Error
#[error(" 0 caught fire")]
Combustion(String),
#[error(" 0 exploded")]
Explosion(String),
I also implement functions to create each error variant, because that allows me to do the Into<String> trick, and can sometimes come in handy when creating errors from other places with .map_err() (more on that later).
For example, the impl for the above Error would probably be:
impl Error
fn combustion(desc: impl Into<String>) -> Self
Self::Combustion(desc.into())
fn explosion(desc: impl Into<String>) -> Self
Self::Explosion(desc.into())
It s a tedious bit of boilerplate, and you can use the thiserror-ext crate s thiserror_ext::Construct derive macro to do the hard work for you, if you like.
It, too, knows all about the Into<String> trick.
Banish map_err (well, mostly)
The newer mediocre programmer, who is just dipping their toe in the water of Rust, might write file handling code that looks like this:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
.map_err( e Error::FileOpenError(name.as_ref().to_string(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
.map_err( e Error::ReadError(e))?;
String::from_utf8(buf)
.map_err( e Error::EncodingError(e))?
.parse::<u32>()
.map_err( e Error::ParseError(e))
This works great (or it probably does, I haven t actually tested it), but there are a lot of .map_err() calls in there.
They take up over half the function, in fact.
With the power of the From trait and the magic of the ? operator, we can make this a lot tidier.
First off, assume we ve written boilerplate error creation functions (or used thiserror_ext::Construct to do it for us)).
That allows us to simplify the file handling portion of the function a bit:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
// We've dropped the .to_string() out of here...
.map_err( e Error::file_open_error(name.as_ref(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
// ... and the explicit parameter passing out of here
.map_err(Error::read_error)?;
// ...
If that latter .map_err() call looks weird, without the e and such, it s passing a function-as-closure, which just saves on a few characters typing.
Just because we re mediocre, doesn t mean we re not also lazy.
Next, if we implement the From trait for the other two errors, we can make the string-handling lines significantly cleaner.
First, the trait impl:
impl From<std::string::FromUtf8Error> for Error
fn from(e: std::string::FromUtf8Error) -> Self
Self::EncodingError(e)
impl From<std::num::ParseIntError> for Error
fn from(e: std::num::ParseIntError) -> Self
Self::ParseError(e)
(Again, this is boilerplate that can be autogenerated, this time by adding a #[from] tag to the variants you want a From impl on, and thiserror will take care of it for you)
In any event, no matter how you get the From impls, once you have them, the string-handling code becomes practically error-handling-free:
Ok(
String::from_utf8(buf)?
.parse::<u32>()?
)
The ? operator will automatically convert the error from the types returned from each method into the return error type, using From.
The only tiny downside to this is that the ? at the end strips the Result, and so we ve got to wrap the returned value in Ok() to turn it back into a Result for returning.
But I think that s a small price to pay for the removal of those .map_err() calls.
In many cases, my coding process involves just putting a ? after every call that returns a Result, and adding a new Error variant whenever the compiler complains about not being able to convert some new error type.
It s practically zero effort outstanding outcome for the mediocre programmer.
Just Because You re Mediocre, Doesn t Mean You Can t Get Better
To finish off, I d like to point out that mediocrity doesn t imply shoddy work, nor does it mean that you shouldn t keep learning and improving your craft.
One book that I ve recently found extremely helpful is Effective Rust, by David Drysdale.
The author has very kindly put it up to read online, but buying a (paper or ebook) copy would no doubt be appreciated.
The thing about this book, for me, is that it is very readable, even by us mediocre programmers.
The sections are written in a way that really clicked with me.
Some aspects of Rust that I d had trouble understanding for a long time such as lifetimes and the borrow checker, and particularly lifetime elision actually made sense after I d read the appropriate sections.
Finally, a Quick Beg
I m currently subsisting on the kindness of strangers, so if you found something useful (or entertaining) in this post, why not buy me a refreshing beverage?
It helps to know that people like what I m doing, and helps keep me from having to sell my soul to a private equity firm.
.clone().
I scatter them around my code like seeds in a field.
Life s too short to spend time trying to figure out who s borrowing what from whom, if I can just give everyone their own thing.
There are warnings in the Rust book (and everywhere else) about how a clone can be expensive .
While it s true that, yes, making clones of data structures consumes CPU cycles and memory, it very rarely matters.
CPU cycles are (usually) plentiful and RAM (usually) relatively cheap.
Mediocre programmer mental effort is expensive, and not to be spent on premature optimisation.
Also, if you re coming from most any other modern language, Rust is already giving you so much more performance that you re probably ending up ahead of the game, even if you .clone() everything in sight.
If, by some miracle, something I write gets so popular that the expense of all those spurious clones becomes a problem, it might make sense to pay someone much smarter than I to figure out how to make the program a zero-copy masterpiece of efficient code.
Until then clone early and clone often, I say!
Derive Macros are Powerful Magicks
If you start .clone()ing everywhere, pretty quickly you ll be hit with this error:
error[E0599]: no method named clone found for struct Foo in the current scope
This is because not everything can be cloned, and so if you want your thing to be cloned, you need to implement the method yourself.
Well sort of.
One of the things that I find absolutely outstanding about Rust is the derive macro .
These allow you to put a little marker on a struct or enum, and the compiler will write a bunch of code for you!
Clone is one of the available so-called derivable traits , so you add #[derive(Clone)] to your structs, and poof! you can .clone() to your heart s content.
But there are other things that are commonly useful, and so I ve got a set of traits that basically all of my data structures derive:
#[derive(Clone, Debug, Default)]
struct Foo
// ...
Every time I write a struct or enum definition, that line #[derive(Clone, Debug, Default)] goes at the top.
The Debug trait allows you to print a debug representation of the data structure, either with the dbg!() macro, or via the :? format in the format!() macro (and anywhere else that takes a format string).
Being able to say what exactly is that? comes in handy so often, not having a Debug implementation is like programming with one arm tied behind your Aeron.
Meanwhile, the Default trait lets you create an empty instance of your data structure, with all of the fields set to their own default values.
This only works if all the fields themselves implement Default, but a lot of standard types do, so it s rare that you ll define a structure that can t have an auto-derived Default.
Enums are easily handled too, you just mark one variant as the default:
#[derive(Clone, Debug, Default)]
enum Bar
Something(String),
SomethingElse(i32),
#[default] // <== mischief managed
Nothing,
Borrowing is OK, Sometimes
While I previously said that I like and usually use owned values, there are a few situations where I know I can borrow without angering the borrow checker gods, and so I m comfortable doing it.
The first is when I need to pass a value into a function that only needs to take a little look at the value to decide what to do.
For example, if I want to know whether any values in a Vec<u32> are even, I could pass in a Vec, like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(numbers)
println!("EVENS!");
fn has_evens(numbers: Vec<u32>) -> bool
numbers.iter().any( n n % 2 == 0)
Howver, this gets ugly if I m going to use numbers later, like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(numbers)
println!("EVENS!");
// Compiler complains about "value borrowed here after move"
println!("Sum: ", numbers.iter().sum::<u32>());
fn has_evens(numbers: Vec<u32>) -> bool
numbers.iter().any( n n % 2 == 0)
Helpfully, the compiler will suggest I use my old standby, .clone(), to fix this problem.
But I know that the borrow checker won t have a problem with lending that Vec<u32> into has_evens() as a borrowed slice, &[u32], like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(&numbers)
println!("EVENS!");
fn has_evens(numbers: &[u32]) -> bool
numbers.iter().any( n n % 2 == 0)
The general rule I ve got is that if I can take advantage of lifetime elision (a fancy term meaning the compiler can figure it out ), I m probably OK.
In less fancy terms, as long as the compiler doesn t tell me to put 'a anywhere, I m in the green.
On the other hand, the moment the compiler starts using the words explicit lifetime , I nope the heck out of there and start cloning everything in sight.
Another example of using lifetime elision is when I m returning the value of a field from a struct or enum.
In that case, I can usually get away with returning a borrowed value, knowing that the caller will probably just be taking a peek at that value, and throwing it away before the struct itself goes out of scope.
For example:
struct Foo
id: u32,
desc: String,
impl Foo
fn description(&self) -> &str
&self.desc
Returning a reference from a function is practically always a mortal sin for mediocre programmers, but returning one from a struct method is often OK.
In the rare case that the caller does want the reference I return to live for longer, they can always turn it into an owned value themselves, by calling .to_owned().
Avoid the String Tangle
Rust has a couple of different types for representing strings String and &str being the ones you see most often.
There are good reasons for this, however it complicates method signatures when you just want to take some sort of bunch of text , and don t care so much about the messy details.
For example, let s say we have a function that wants to see if the length of the string is even.
Using the logic that since we re just taking a peek at the value passed in, our function might take a string reference, &str, like this:
fn is_even_length(s: &str) -> bool
s.len() % 2 == 0
That seems to work fine, until someone wants to check a formatted string:
fn main()
// The compiler complains about "expected &str , found String "
if is_even_length(format!("my string is ", std::env::args().next().unwrap()))
println!("Even length string");
Since format! returns an owned string, String, rather than a string reference, &str, we ve got a problem.
Of course, it s straightforward to turn the String from format!() into a &str (just prefix it with an &).
But as mediocre programmers, we can t be expected to remember which sort of string all our functions take and add & wherever it s needed, and having to fix everything when the compiler complains is tedious.
The converse can also happen: a method that wants an owned String, and we ve got a &str (say, because we re passing in a string literal, like "Hello, world!").
In this case, we need to use one of the plethora of available turn this into a String mechanisms (.to_string(), .to_owned(), String::from(), and probably a few others I ve forgotten), on the value before we pass it in, which gets ugly real fast.
For these reasons, I never take a String or an &str as an argument.
Instead, I use the Power of Traits to let callers pass in anything that is, or can be turned into, a string.
Let us have some examples.
First off, if I would normally use &str as the type, I instead use impl AsRef<str>:
fn is_even_length(s: impl AsRef<str>) -> bool
s.as_ref().len() % 2 == 0
Note that I had to throw in an extra as_ref() call in there, but now I can call this with either a String or a &str and get an answer.
Now, if I want to be given a String (presumably because I plan on taking ownership of the value, say because I m creating a new instance of a struct with it), I use impl Into<String> as my type:
struct Foo
id: u32,
desc: String,
impl Foo
fn new(id: u32, desc: impl Into<String>) -> Self
Self id, desc: desc.into()
We have to call .into() on our desc argument, which makes the struct building a bit uglier, but I d argue that s a small price to pay for being able to call both Foo::new(1, "this is a thing") and Foo::new(2, format!("This is a thing named name ")) without caring what sort of string is involved.
Always Have an Error Enum
Rust s error handing mechanism (Results everywhere), along with the quality-of-life sugar surrounding it (like the short-circuit operator, ?), is a delightfully ergonomic approach to error handling.
To make life easy for mediocre programmers, I recommend starting every project with an Error enum, that derives thiserror::Error, and using that in every method and function that returns a Result.
How you structure your Error type from there is less cut-and-dried, but typically I ll create a separate enum variant for each type of error I want to have a different description.
With thiserror, it s easy to then attach those descriptions:
#[derive(Clone, Debug, thiserror::Error)]
enum Error
#[error(" 0 caught fire")]
Combustion(String),
#[error(" 0 exploded")]
Explosion(String),
I also implement functions to create each error variant, because that allows me to do the Into<String> trick, and can sometimes come in handy when creating errors from other places with .map_err() (more on that later).
For example, the impl for the above Error would probably be:
impl Error
fn combustion(desc: impl Into<String>) -> Self
Self::Combustion(desc.into())
fn explosion(desc: impl Into<String>) -> Self
Self::Explosion(desc.into())
It s a tedious bit of boilerplate, and you can use the thiserror-ext crate s thiserror_ext::Construct derive macro to do the hard work for you, if you like.
It, too, knows all about the Into<String> trick.
Banish map_err (well, mostly)
The newer mediocre programmer, who is just dipping their toe in the water of Rust, might write file handling code that looks like this:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
.map_err( e Error::FileOpenError(name.as_ref().to_string(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
.map_err( e Error::ReadError(e))?;
String::from_utf8(buf)
.map_err( e Error::EncodingError(e))?
.parse::<u32>()
.map_err( e Error::ParseError(e))
This works great (or it probably does, I haven t actually tested it), but there are a lot of .map_err() calls in there.
They take up over half the function, in fact.
With the power of the From trait and the magic of the ? operator, we can make this a lot tidier.
First off, assume we ve written boilerplate error creation functions (or used thiserror_ext::Construct to do it for us)).
That allows us to simplify the file handling portion of the function a bit:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
// We've dropped the .to_string() out of here...
.map_err( e Error::file_open_error(name.as_ref(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
// ... and the explicit parameter passing out of here
.map_err(Error::read_error)?;
// ...
If that latter .map_err() call looks weird, without the e and such, it s passing a function-as-closure, which just saves on a few characters typing.
Just because we re mediocre, doesn t mean we re not also lazy.
Next, if we implement the From trait for the other two errors, we can make the string-handling lines significantly cleaner.
First, the trait impl:
impl From<std::string::FromUtf8Error> for Error
fn from(e: std::string::FromUtf8Error) -> Self
Self::EncodingError(e)
impl From<std::num::ParseIntError> for Error
fn from(e: std::num::ParseIntError) -> Self
Self::ParseError(e)
(Again, this is boilerplate that can be autogenerated, this time by adding a #[from] tag to the variants you want a From impl on, and thiserror will take care of it for you)
In any event, no matter how you get the From impls, once you have them, the string-handling code becomes practically error-handling-free:
Ok(
String::from_utf8(buf)?
.parse::<u32>()?
)
The ? operator will automatically convert the error from the types returned from each method into the return error type, using From.
The only tiny downside to this is that the ? at the end strips the Result, and so we ve got to wrap the returned value in Ok() to turn it back into a Result for returning.
But I think that s a small price to pay for the removal of those .map_err() calls.
In many cases, my coding process involves just putting a ? after every call that returns a Result, and adding a new Error variant whenever the compiler complains about not being able to convert some new error type.
It s practically zero effort outstanding outcome for the mediocre programmer.
Just Because You re Mediocre, Doesn t Mean You Can t Get Better
To finish off, I d like to point out that mediocrity doesn t imply shoddy work, nor does it mean that you shouldn t keep learning and improving your craft.
One book that I ve recently found extremely helpful is Effective Rust, by David Drysdale.
The author has very kindly put it up to read online, but buying a (paper or ebook) copy would no doubt be appreciated.
The thing about this book, for me, is that it is very readable, even by us mediocre programmers.
The sections are written in a way that really clicked with me.
Some aspects of Rust that I d had trouble understanding for a long time such as lifetimes and the borrow checker, and particularly lifetime elision actually made sense after I d read the appropriate sections.
Finally, a Quick Beg
I m currently subsisting on the kindness of strangers, so if you found something useful (or entertaining) in this post, why not buy me a refreshing beverage?
It helps to know that people like what I m doing, and helps keep me from having to sell my soul to a private equity firm.
error[E0599]: no method named clone found for struct Foo in the current scope
#[derive(Clone, Debug, Default)]
struct Foo
// ...
#[derive(Clone, Debug, Default)]
enum Bar
Something(String),
SomethingElse(i32),
#[default] // <== mischief managed
Nothing,
Vec<u32> are even, I could pass in a Vec, like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(numbers)
println!("EVENS!");
fn has_evens(numbers: Vec<u32>) -> bool
numbers.iter().any( n n % 2 == 0)
numbers later, like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(numbers)
println!("EVENS!");
// Compiler complains about "value borrowed here after move"
println!("Sum: ", numbers.iter().sum::<u32>());
fn has_evens(numbers: Vec<u32>) -> bool
numbers.iter().any( n n % 2 == 0)
.clone(), to fix this problem.
But I know that the borrow checker won t have a problem with lending that Vec<u32> into has_evens() as a borrowed slice, &[u32], like this:
fn main()
let numbers = vec![0u32, 1, 2, 3, 4, 5];
if has_evens(&numbers)
println!("EVENS!");
fn has_evens(numbers: &[u32]) -> bool
numbers.iter().any( n n % 2 == 0)
'a anywhere, I m in the green.
On the other hand, the moment the compiler starts using the words explicit lifetime , I nope the heck out of there and start cloning everything in sight.
Another example of using lifetime elision is when I m returning the value of a field from a struct or enum.
In that case, I can usually get away with returning a borrowed value, knowing that the caller will probably just be taking a peek at that value, and throwing it away before the struct itself goes out of scope.
For example:
struct Foo
id: u32,
desc: String,
impl Foo
fn description(&self) -> &str
&self.desc
.to_owned().
Avoid the String Tangle
Rust has a couple of different types for representing strings String and &str being the ones you see most often.
There are good reasons for this, however it complicates method signatures when you just want to take some sort of bunch of text , and don t care so much about the messy details.
For example, let s say we have a function that wants to see if the length of the string is even.
Using the logic that since we re just taking a peek at the value passed in, our function might take a string reference, &str, like this:
fn is_even_length(s: &str) -> bool
s.len() % 2 == 0
That seems to work fine, until someone wants to check a formatted string:
fn main()
// The compiler complains about "expected &str , found String "
if is_even_length(format!("my string is ", std::env::args().next().unwrap()))
println!("Even length string");
Since format! returns an owned string, String, rather than a string reference, &str, we ve got a problem.
Of course, it s straightforward to turn the String from format!() into a &str (just prefix it with an &).
But as mediocre programmers, we can t be expected to remember which sort of string all our functions take and add & wherever it s needed, and having to fix everything when the compiler complains is tedious.
The converse can also happen: a method that wants an owned String, and we ve got a &str (say, because we re passing in a string literal, like "Hello, world!").
In this case, we need to use one of the plethora of available turn this into a String mechanisms (.to_string(), .to_owned(), String::from(), and probably a few others I ve forgotten), on the value before we pass it in, which gets ugly real fast.
For these reasons, I never take a String or an &str as an argument.
Instead, I use the Power of Traits to let callers pass in anything that is, or can be turned into, a string.
Let us have some examples.
First off, if I would normally use &str as the type, I instead use impl AsRef<str>:
fn is_even_length(s: impl AsRef<str>) -> bool
s.as_ref().len() % 2 == 0
Note that I had to throw in an extra as_ref() call in there, but now I can call this with either a String or a &str and get an answer.
Now, if I want to be given a String (presumably because I plan on taking ownership of the value, say because I m creating a new instance of a struct with it), I use impl Into<String> as my type:
struct Foo
id: u32,
desc: String,
impl Foo
fn new(id: u32, desc: impl Into<String>) -> Self
Self id, desc: desc.into()
We have to call .into() on our desc argument, which makes the struct building a bit uglier, but I d argue that s a small price to pay for being able to call both Foo::new(1, "this is a thing") and Foo::new(2, format!("This is a thing named name ")) without caring what sort of string is involved.
Always Have an Error Enum
Rust s error handing mechanism (Results everywhere), along with the quality-of-life sugar surrounding it (like the short-circuit operator, ?), is a delightfully ergonomic approach to error handling.
To make life easy for mediocre programmers, I recommend starting every project with an Error enum, that derives thiserror::Error, and using that in every method and function that returns a Result.
How you structure your Error type from there is less cut-and-dried, but typically I ll create a separate enum variant for each type of error I want to have a different description.
With thiserror, it s easy to then attach those descriptions:
#[derive(Clone, Debug, thiserror::Error)]
enum Error
#[error(" 0 caught fire")]
Combustion(String),
#[error(" 0 exploded")]
Explosion(String),
I also implement functions to create each error variant, because that allows me to do the Into<String> trick, and can sometimes come in handy when creating errors from other places with .map_err() (more on that later).
For example, the impl for the above Error would probably be:
impl Error
fn combustion(desc: impl Into<String>) -> Self
Self::Combustion(desc.into())
fn explosion(desc: impl Into<String>) -> Self
Self::Explosion(desc.into())
It s a tedious bit of boilerplate, and you can use the thiserror-ext crate s thiserror_ext::Construct derive macro to do the hard work for you, if you like.
It, too, knows all about the Into<String> trick.
Banish map_err (well, mostly)
The newer mediocre programmer, who is just dipping their toe in the water of Rust, might write file handling code that looks like this:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
.map_err( e Error::FileOpenError(name.as_ref().to_string(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
.map_err( e Error::ReadError(e))?;
String::from_utf8(buf)
.map_err( e Error::EncodingError(e))?
.parse::<u32>()
.map_err( e Error::ParseError(e))
This works great (or it probably does, I haven t actually tested it), but there are a lot of .map_err() calls in there.
They take up over half the function, in fact.
With the power of the From trait and the magic of the ? operator, we can make this a lot tidier.
First off, assume we ve written boilerplate error creation functions (or used thiserror_ext::Construct to do it for us)).
That allows us to simplify the file handling portion of the function a bit:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
// We've dropped the .to_string() out of here...
.map_err( e Error::file_open_error(name.as_ref(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
// ... and the explicit parameter passing out of here
.map_err(Error::read_error)?;
// ...
If that latter .map_err() call looks weird, without the e and such, it s passing a function-as-closure, which just saves on a few characters typing.
Just because we re mediocre, doesn t mean we re not also lazy.
Next, if we implement the From trait for the other two errors, we can make the string-handling lines significantly cleaner.
First, the trait impl:
impl From<std::string::FromUtf8Error> for Error
fn from(e: std::string::FromUtf8Error) -> Self
Self::EncodingError(e)
impl From<std::num::ParseIntError> for Error
fn from(e: std::num::ParseIntError) -> Self
Self::ParseError(e)
(Again, this is boilerplate that can be autogenerated, this time by adding a #[from] tag to the variants you want a From impl on, and thiserror will take care of it for you)
In any event, no matter how you get the From impls, once you have them, the string-handling code becomes practically error-handling-free:
Ok(
String::from_utf8(buf)?
.parse::<u32>()?
)
The ? operator will automatically convert the error from the types returned from each method into the return error type, using From.
The only tiny downside to this is that the ? at the end strips the Result, and so we ve got to wrap the returned value in Ok() to turn it back into a Result for returning.
But I think that s a small price to pay for the removal of those .map_err() calls.
In many cases, my coding process involves just putting a ? after every call that returns a Result, and adding a new Error variant whenever the compiler complains about not being able to convert some new error type.
It s practically zero effort outstanding outcome for the mediocre programmer.
Just Because You re Mediocre, Doesn t Mean You Can t Get Better
To finish off, I d like to point out that mediocrity doesn t imply shoddy work, nor does it mean that you shouldn t keep learning and improving your craft.
One book that I ve recently found extremely helpful is Effective Rust, by David Drysdale.
The author has very kindly put it up to read online, but buying a (paper or ebook) copy would no doubt be appreciated.
The thing about this book, for me, is that it is very readable, even by us mediocre programmers.
The sections are written in a way that really clicked with me.
Some aspects of Rust that I d had trouble understanding for a long time such as lifetimes and the borrow checker, and particularly lifetime elision actually made sense after I d read the appropriate sections.
Finally, a Quick Beg
I m currently subsisting on the kindness of strangers, so if you found something useful (or entertaining) in this post, why not buy me a refreshing beverage?
It helps to know that people like what I m doing, and helps keep me from having to sell my soul to a private equity firm.
fn is_even_length(s: &str) -> bool
s.len() % 2 == 0
fn main()
// The compiler complains about "expected &str , found String "
if is_even_length(format!("my string is ", std::env::args().next().unwrap()))
println!("Even length string");
fn is_even_length(s: impl AsRef<str>) -> bool
s.as_ref().len() % 2 == 0
struct Foo
id: u32,
desc: String,
impl Foo
fn new(id: u32, desc: impl Into<String>) -> Self
Self id, desc: desc.into()
Error Enum
Rust s error handing mechanism (Results everywhere), along with the quality-of-life sugar surrounding it (like the short-circuit operator, ?), is a delightfully ergonomic approach to error handling.
To make life easy for mediocre programmers, I recommend starting every project with an Error enum, that derives thiserror::Error, and using that in every method and function that returns a Result.
How you structure your Error type from there is less cut-and-dried, but typically I ll create a separate enum variant for each type of error I want to have a different description.
With thiserror, it s easy to then attach those descriptions:
#[derive(Clone, Debug, thiserror::Error)]
enum Error
#[error(" 0 caught fire")]
Combustion(String),
#[error(" 0 exploded")]
Explosion(String),
Into<String> trick, and can sometimes come in handy when creating errors from other places with .map_err() (more on that later).
For example, the impl for the above Error would probably be:
impl Error
fn combustion(desc: impl Into<String>) -> Self
Self::Combustion(desc.into())
fn explosion(desc: impl Into<String>) -> Self
Self::Explosion(desc.into())
thiserror-ext crate s thiserror_ext::Construct derive macro to do the hard work for you, if you like.
It, too, knows all about the Into<String> trick.
Banish map_err (well, mostly)
The newer mediocre programmer, who is just dipping their toe in the water of Rust, might write file handling code that looks like this:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
.map_err( e Error::FileOpenError(name.as_ref().to_string(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
.map_err( e Error::ReadError(e))?;
String::from_utf8(buf)
.map_err( e Error::EncodingError(e))?
.parse::<u32>()
.map_err( e Error::ParseError(e))
This works great (or it probably does, I haven t actually tested it), but there are a lot of .map_err() calls in there.
They take up over half the function, in fact.
With the power of the From trait and the magic of the ? operator, we can make this a lot tidier.
First off, assume we ve written boilerplate error creation functions (or used thiserror_ext::Construct to do it for us)).
That allows us to simplify the file handling portion of the function a bit:
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
// We've dropped the .to_string() out of here...
.map_err( e Error::file_open_error(name.as_ref(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
// ... and the explicit parameter passing out of here
.map_err(Error::read_error)?;
// ...
If that latter .map_err() call looks weird, without the e and such, it s passing a function-as-closure, which just saves on a few characters typing.
Just because we re mediocre, doesn t mean we re not also lazy.
Next, if we implement the From trait for the other two errors, we can make the string-handling lines significantly cleaner.
First, the trait impl:
impl From<std::string::FromUtf8Error> for Error
fn from(e: std::string::FromUtf8Error) -> Self
Self::EncodingError(e)
impl From<std::num::ParseIntError> for Error
fn from(e: std::num::ParseIntError) -> Self
Self::ParseError(e)
(Again, this is boilerplate that can be autogenerated, this time by adding a #[from] tag to the variants you want a From impl on, and thiserror will take care of it for you)
In any event, no matter how you get the From impls, once you have them, the string-handling code becomes practically error-handling-free:
Ok(
String::from_utf8(buf)?
.parse::<u32>()?
)
The ? operator will automatically convert the error from the types returned from each method into the return error type, using From.
The only tiny downside to this is that the ? at the end strips the Result, and so we ve got to wrap the returned value in Ok() to turn it back into a Result for returning.
But I think that s a small price to pay for the removal of those .map_err() calls.
In many cases, my coding process involves just putting a ? after every call that returns a Result, and adding a new Error variant whenever the compiler complains about not being able to convert some new error type.
It s practically zero effort outstanding outcome for the mediocre programmer.
Just Because You re Mediocre, Doesn t Mean You Can t Get Better
To finish off, I d like to point out that mediocrity doesn t imply shoddy work, nor does it mean that you shouldn t keep learning and improving your craft.
One book that I ve recently found extremely helpful is Effective Rust, by David Drysdale.
The author has very kindly put it up to read online, but buying a (paper or ebook) copy would no doubt be appreciated.
The thing about this book, for me, is that it is very readable, even by us mediocre programmers.
The sections are written in a way that really clicked with me.
Some aspects of Rust that I d had trouble understanding for a long time such as lifetimes and the borrow checker, and particularly lifetime elision actually made sense after I d read the appropriate sections.
Finally, a Quick Beg
I m currently subsisting on the kindness of strangers, so if you found something useful (or entertaining) in this post, why not buy me a refreshing beverage?
It helps to know that people like what I m doing, and helps keep me from having to sell my soul to a private equity firm.
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
.map_err( e Error::FileOpenError(name.as_ref().to_string(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
.map_err( e Error::ReadError(e))?;
String::from_utf8(buf)
.map_err( e Error::EncodingError(e))?
.parse::<u32>()
.map_err( e Error::ParseError(e))
fn read_u32_from_file(name: impl AsRef<str>) -> Result<u32, Error>
let mut f = File::open(name.as_ref())
// We've dropped the .to_string() out of here...
.map_err( e Error::file_open_error(name.as_ref(), e))?;
let mut buf = vec![0u8; 30];
f.read(&mut buf)
// ... and the explicit parameter passing out of here
.map_err(Error::read_error)?;
// ...
impl From<std::string::FromUtf8Error> for Error
fn from(e: std::string::FromUtf8Error) -> Self
Self::EncodingError(e)
impl From<std::num::ParseIntError> for Error
fn from(e: std::num::ParseIntError) -> Self
Self::ParseError(e)
Ok(
String::from_utf8(buf)?
.parse::<u32>()?
)
 Or "How I've halved the execution time of our tests by removing ten lines".
Catchy, huh? Also not exactly true, but quite close. Enjoy!
Molecule?!
"
Or "How I've halved the execution time of our tests by removing ten lines".
Catchy, huh? Also not exactly true, but quite close. Enjoy!
Molecule?!
" It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
It s been around 6 months since the GNOME Foundation was joined by our new Executive Director, Holly Million, and the board and I wanted to update members on the Foundation s current status and some exciting upcoming changes.
 With
With 
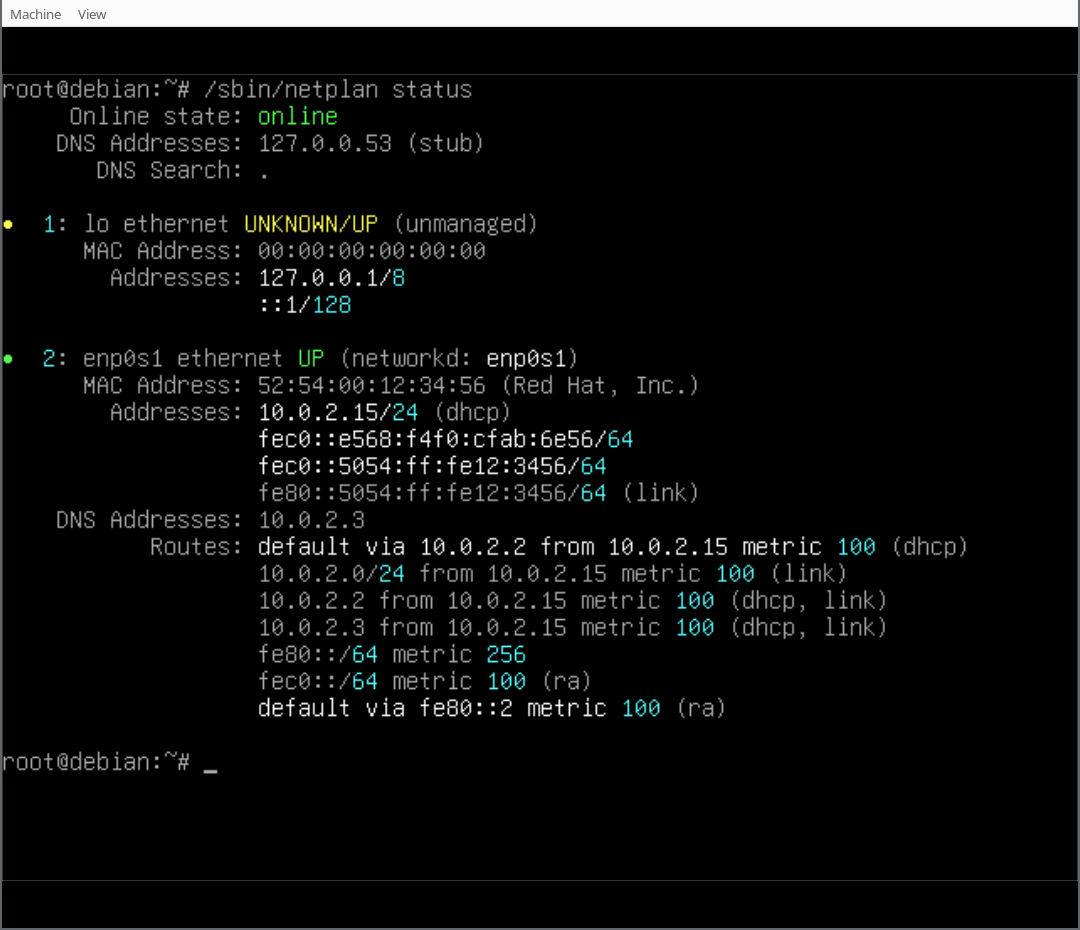
 (There s a handy
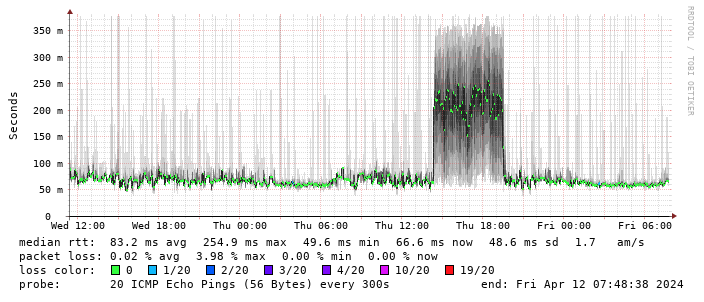
(There s a handy 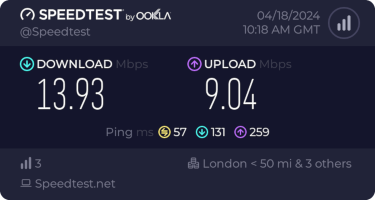 This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
This is disappointing, but if it turns out to be a problem I can look at mounting it externally. I also assume as 5G is gradually rolled out further things will naturally improve, but that might be wishful thinking on my part.
Rather than wait until my main link had a problem I decided to try a day working over the 5G connection. I spend a lot of my time either in browser based apps or accessing remote systems via SSH, so I m reasonably sensitive to a jittery or otherwise flaky connection. I picked a day that I did not have any meetings planned, but as it happened I ended up with an adhoc video call arranged. I m pleased to say that it all worked just fine; definitely noticeable as slower than the FTTP connection (to be expected), but all workable and even the video call was fine (at least from my end). Looking at the traffic graph shows the expected ~ 10Mb/s peak (actually a little higher, and looking at the FTTP stats for previous days not out of keeping with what we see there), and you can just about see the ~ 3Mb/s symmetric use by the video call at 2pm:
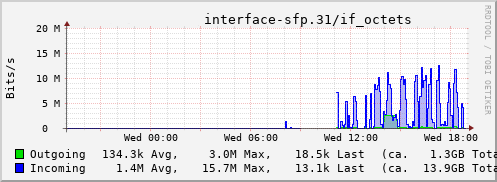 The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.
The test run also helped iron out the fact that the content filter was still enabled on the SIM, but that was easily resolved.
Up next, vaguely automatic failover.

 Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to
Years ago, at what I think I remember was DebConf 15, I hacked for a while
on debhelper to